The ORCFLO Indexis an independent benchmark that evaluates large language models the way business professionals actually use them — across 40 real-world tasks spanning analysis, writing, extraction, summarization, and behavioral reliability. Each model is scored on three dimensions (quality, cost, and speed) by a panel of four independent judges. This report evaluates Claude Opus 4.7 in the context of 39 models from Anthropic, OpenAI, Google, Mistral, and others.
Claude Opus 4.7
Claude Opus 4.7 is the best writer and analyst in a field of 39 models, taking #1 in both categories. But catastrophic summarization failures on S2 (Bullet Compression) and S3 (Multi-Section Document Summary), combined with a drop in output consistency, drag its overall rank to #11 — a step back from Opus 4.6's #2 position. It's faster than its predecessor but more expensive, and the quality regression demands investigation before deployment in summarization-heavy workflows.
Key Findings
- #1 in Analysis and Writing. Opus 4.7 tops all 39 models in both categories — scoring 94.0 in Analysis (edging GPT 5.4 Pro at 93.8) and 94.0 in Writing (a 4.4-point jump over Opus 4.6).
- Summarization collapse. Two cases scored critically low: S2 (Bullet Compression — producing exact bullet counts under hard simultaneous constraints) at 18.8, and S3 (Multi-Section Document Summary — parsing long documents into a specific three-part format within a word limit) at 2.8. This dragged the category to 59.6 — rank #37 of 39 and a 28-point regression from Opus 4.6. Under investigation.
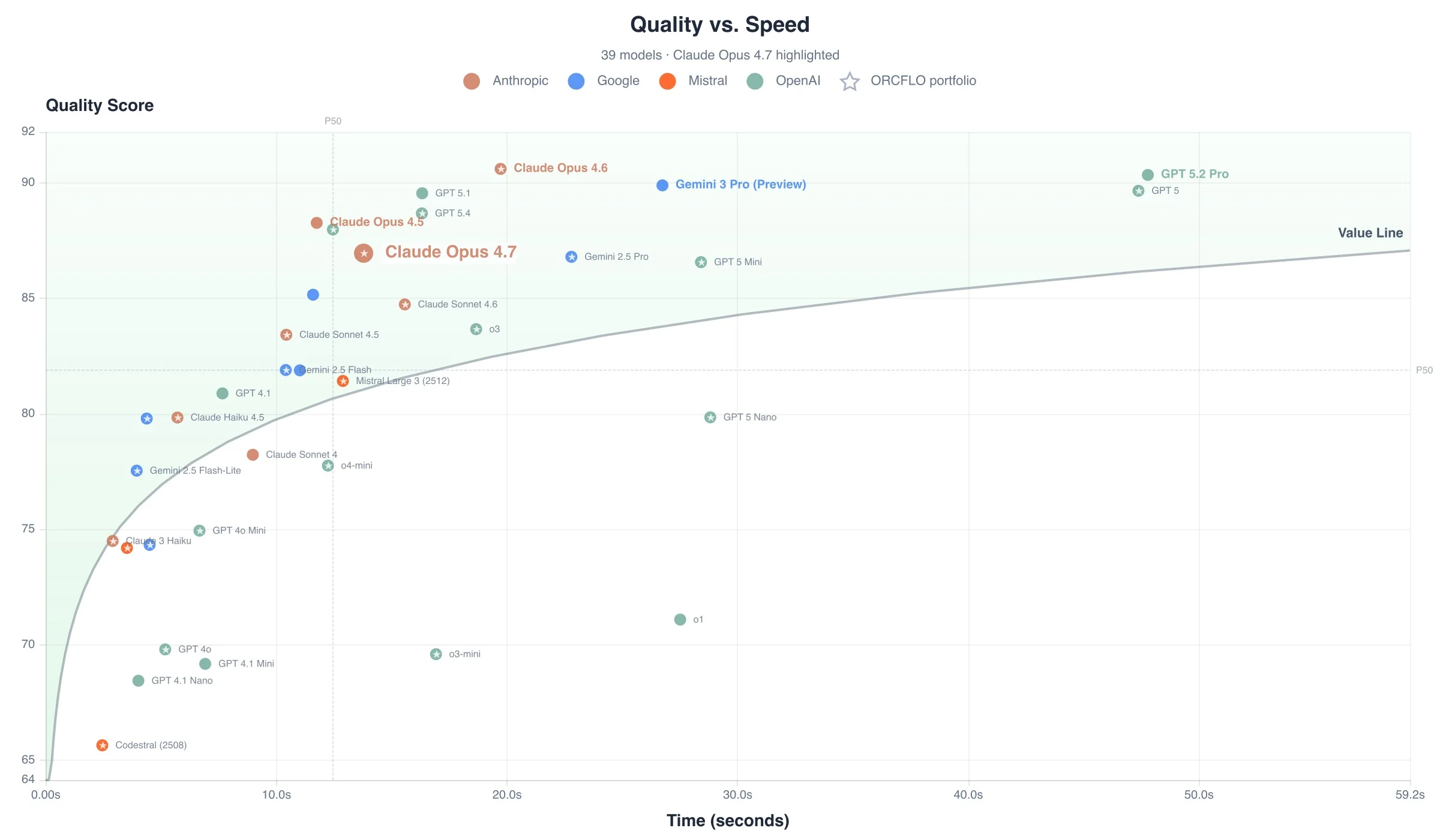
- 30% faster, 16% more expensive. Average response time dropped from 19.7s to 13.8s versus Opus 4.6, but the total cost to complete all 40 tests rose from 0.023 to 0.026 credits.
- Output consistency regressed. Dropped from 99.2 (rank #1) on Opus 4.6 to 89.5 (rank #23) — a significant step back in behavioral reliability.
Model Performance: Quality & Cost
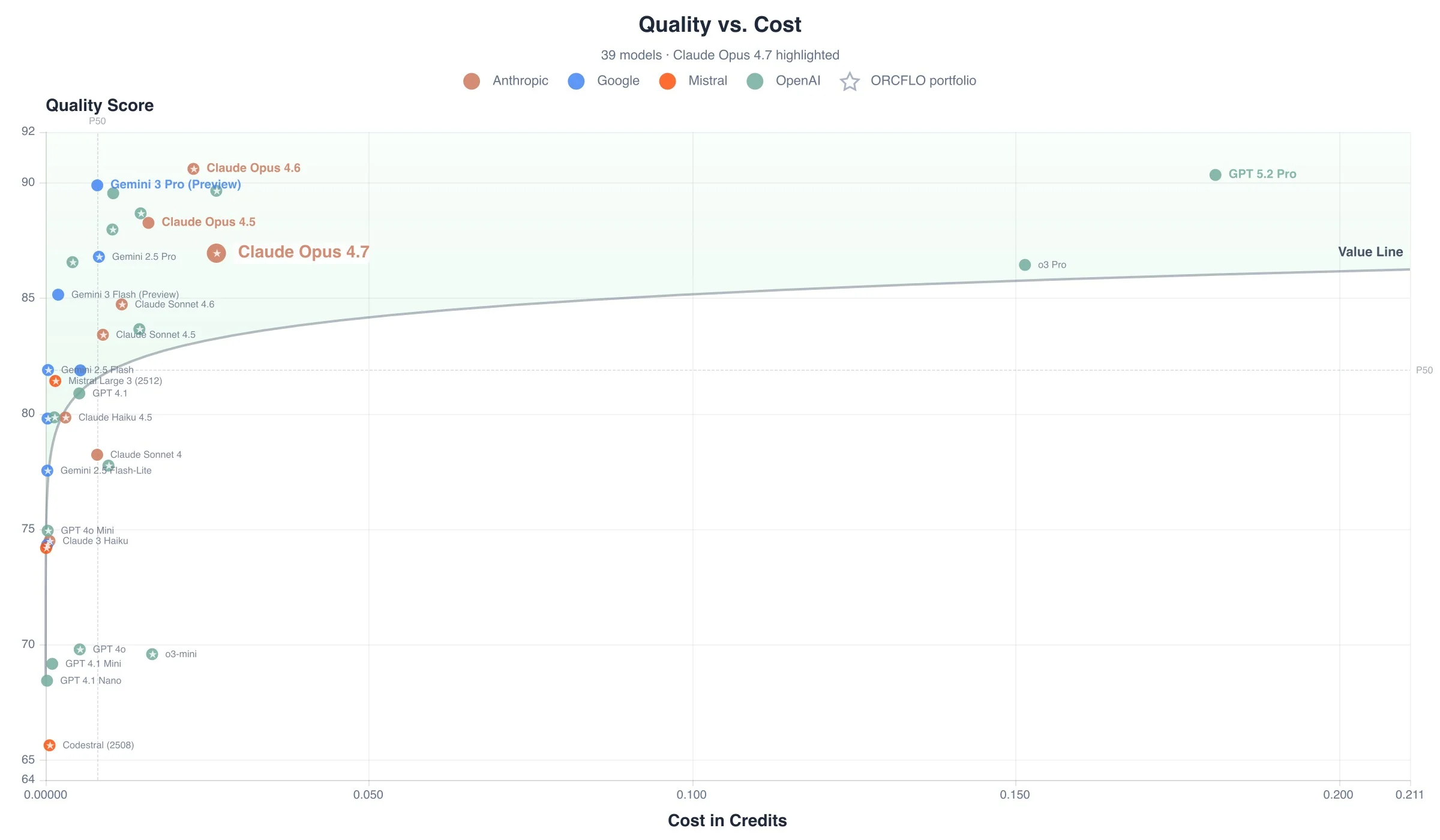
The chart below plots quality against cost for all 39 models in the ORCFLO Index. Each dot represents the average quality score a model achieved across our full basket of 40 real-world business tasks, alongside the total cost in credits to complete the entire test suite. Models in the upper-left quadrant deliver the highest quality at the lowest cost.
Model Performance: Quality & Time Elapsed
Quality alone doesn’t tell the full story — response time determines whether a model is viable for time-sensitive workflows. The chart below plots each model’s quality score against the total time required to complete all 40 tests. Models in the upper-left deliver the best quality with the least delay.
Category Scorecard
The ORCFLO Indexevaluates models using real-world business tasks — not academic puzzles or synthetic benchmarks. Each test case is designed to expose specific differences in how models handle tasks that professionals actually encounter: strategic analysis, document extraction, business writing, summarization, and behavioral reliability. Scores are averaged across five cases per category, and each category is ranked independently across all 39 models.
| Category | Score | Rank | Tier | vs. Opus 4.6 |
|---|---|---|---|---|
| Abilities — Core language tasks: what the model can produce when given a well-formed prompt. | ||||
| Analysis Reasoning, strategic judgment, disqualifying-factor detection | #1 | Leader | +0.6 | |
| Extraction Field accuracy, null handling, format compliance, zero fabrication | #2 | Leader | +10.9 | |
| Summarization Compression quality, key-point retention, length compliance | #37 | Trailing | −28.4 | |
| Writing Tone, structure, persuasion, audience adaptation | #1 | Leader | +4.4 | |
| Behaviors — How the model acts under pressure: reliability, compliance, and restraint. | ||||
| Hallucination Fabrication detection, factual grounding, source fidelity | #13 | Strong | −2.3 | |
| Instruction Following Constraint adherence, format compliance, multi-part directives | #16 | Strong | −3.2 | |
| Refusal Calibration Appropriate refusal vs. over-refusal on legitimate requests | #9 | Leader | −1.7 | |
| Stability — Repeatability and predictability across identical inputs. | ||||
| Output Consistency Run-to-run reproducibility, format stability, score variance | #23 | Contender | −9.7 | |
Strengths and Weaknesses
Strengths
- #1 in Analysis and Writing — the only model to top both categories. Particularly strong on tasks requiring strategic judgment and nuanced prose.
- #2 in Extraction — a 10.9-point jump from Opus 4.6, trailing only Gemini 3 Pro Preview. Reliable structured output with accurate null handling.
- 30% faster than Opus 4.6 — average response time dropped from 19.7s to 13.8s with no increase in quality for its strong categories.
Cautions
- Summarization failure — S2 (Bullet Compression) and S3 (Multi-Section Document Summary) scored 18.8 and 2.8 respectively, dragging the category to #37 of 39. A 28-point regression from Opus 4.6. Under investigation.
- Output consistency dropped sharply — from #1 (99.2) to #23 (89.5). Behavioral reliability is weaker than its predecessor.
- Most expensive Anthropic model — 0.026 credits total to complete all 40 tests, higher than Opus 4.6 (0.023 cr) and more than double Sonnet 4.6 (0.012 cr). Cost rank #33 of 39.
Head-to-Head: Frontier Models
Claude Opus 4.7 is Anthropic’s premiere frontier model in the ORCFLO Index. The table below compares it against the top-performing models from each major provider. Tier assignments use 25% quartiles across the full 39-model field.
| Model | Quality Avg | Quality Rank | Cost Rank | Speed Rank | Tier |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 90.6 | #2 | #31 | #28 | Leader |
| GPT 5 | 89.7 | #6 | #32 | #34 | Leader |
| Gemini 3 Pro (Preview) | 89.9 | #5 | #20 | #30 | Leader |
| GPT 5.4 | 88.7 | #8 | #28 | #24 | Leader |
| Claude Opus 4.7 | 87 | #11 | #33 | #22 | Strong |
| Gemini 2.5 Pro | 86.8 | #12 | #21 | #29 | Strong |
| Claude Sonnet 4.6 | 84.7 | #16 | #26 | #23 | Strong |
When to Use Claude Opus 4.7
The ORCFLO Index
This evaluation covers 40 cases across 8 categories. All tasks are text-only and English-only. Code generation, multi-turn conversation, multimodal tasks, and agentic workflows are not tested. All four judge models (Gemini 2.5 Pro, Claude Opus 4.6, GPT 5.2, and Mistral Large) are also contestants in the benchmark, which introduces potential scoring bias. We actively monitor for judge bias to ensure that no judge can systematically advantage its own provider's models. Cost and speed measurements reflect API pricing and latency as of the test date (April 2026) and will change as providers update their offerings.
How We Test
The ORCFLO Indexevaluates large language models across three independent dimensions — quality, cost, and speed — using real-world business tasks designed to expose the differences that matter for model selection. Each model is scored by a panel of four independent judges to reduce single-model bias.
- Test Cases
- 40 cases across 8 categories spanning Abilities (Analysis, Extraction, Summarization, Writing), Behaviors (Hallucination, Instruction Following, Refusal Calibration), and Stability (Output Consistency).
- Judge Panel
- Gemini 2.5 Pro, Claude Opus 4.6, GPT-5.2, Mistral Large. Each judge scores independently. Final score is the average across all four judges.
- Scoring
- Three independent ranks: quality (higher is better), cost (lower is better), speed (faster is better). No composite score — because composite scores hide the tradeoffs that drive model selection decisions.
- Tier Definitions
- LeaderTop 25%Ranks 1–10Strong25–50%Ranks 11–20Contender50–75%Ranks 21–30TrailingBottom 25%Ranks 31–39
Full methodology, case descriptions, and historical results are available at orcflo.com/explore/models.